



خطاهای تازه در AI Overview گوگل، از اشتباه در شمارش حروف کلمات ساده تا املای نادرست واژهها، دوباره محدودیت بنیادی مدلهای زبانی بزرگ در فهم ساختار واقعی زبان را برجسته کرده است.
به گزارش سیبوم، پس از آنکه کاربران گزارش دادند هوش مصنوعی گوگل در پاسخ به سوالاتی ساده مانند «چند حرف P در کلمه Google وجود دارد؟» پاسخهای اشتباه میدهد، بحث قدیمی ناتوانی مدلهای زبانی در هجی کردن دوباره داغ شد. مدلهای هوش مصنوعی گوگل که اکنون مرکز اصلی موتور جستوجوی این شرکت هستند، کلمات سادهای مثل «Poop» یا «Journalism» را نیز با خطاهای عجیب هجی کرده و حتی نامهای خاص را بهغلط نوشتهاند.
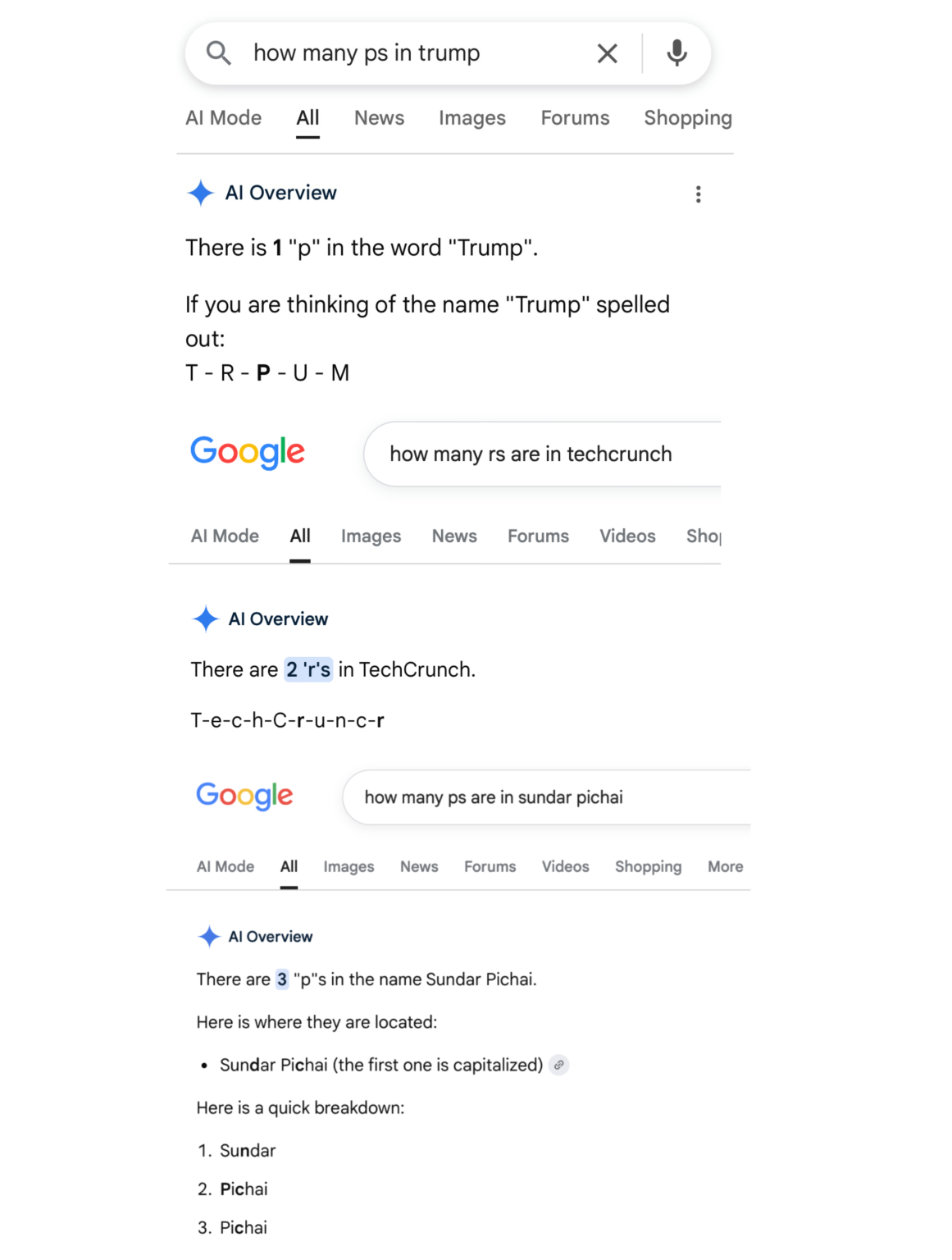
محققان حوزه هوش مصنوعی تأکید دارند این مشکل به «توکنایزرها» برمیگردد. برخلاف انسانها، مدلهای زبانی مبتنی بر معماری Transformer متن را به صورت حروف یا کلمات مجزا نمیخوانند؛ آنها متن را به «توکن» تبدیل کرده و به کدهای عددی ترجمه میکنند. از نظر این مدلها، مفهوم «حرف» (Letter) به معنای انسانی آن وجود ندارد و همین «ابهام» باعث میشود مدلها در شمارش دقیق حروف یا هجی کردن ساده شکست بخورند. با وجود توانایی بالای این مدلها در برنامهنویسی و حل مسائل پیچیده ریاضی، این ناتوانی در املا یادآوری میکند که هوش مصنوعی علیرغم ظاهر هوشمندش، همچنان در پردازشهای پایه ضعف دارد و نباید بدون بازبینی انسانی به خروجیهای آن اعتماد کرد.
